I am currently working as an applied scientist at Landing AI, which is AI startup founded by Andrew Ng. I was a NSF funded PhD student of Computer Science at North Carolina State University under the direction of Dr. Tim Menzies.
Before coming to NC State, I was a visiting student of Automation Department at Tshinghua University from Mar. 2012 to May. 2013, where I worked with Dr. Feifei Gao, mainly focusing on signal processing in wireless communication networks. I earned my M.S. in Electrical Engineering from Beijing University of Posts and Telecommunications, China, in Mar. 2012 and B.S. in Electrical Engineering from Nanjing Tech University, China, in Jun. 2009. I was an intern at Software Engineering group of ABB Corporate Research Center US in 2016 summer.
Email / CV / Google Scholar / LinkedIn / Github
My research topics mainly focus on how to apply next generation of AI techniques to help improve software quality and aid software process. Techniques that I'm interested in (but not limited to) are transfer learning, deep learning and search-based optimization. My research question is always: can we do "it" better and faster?
Wei Fu, Tim Menzies, Vivek Nair
arXiv Preprint, 2017
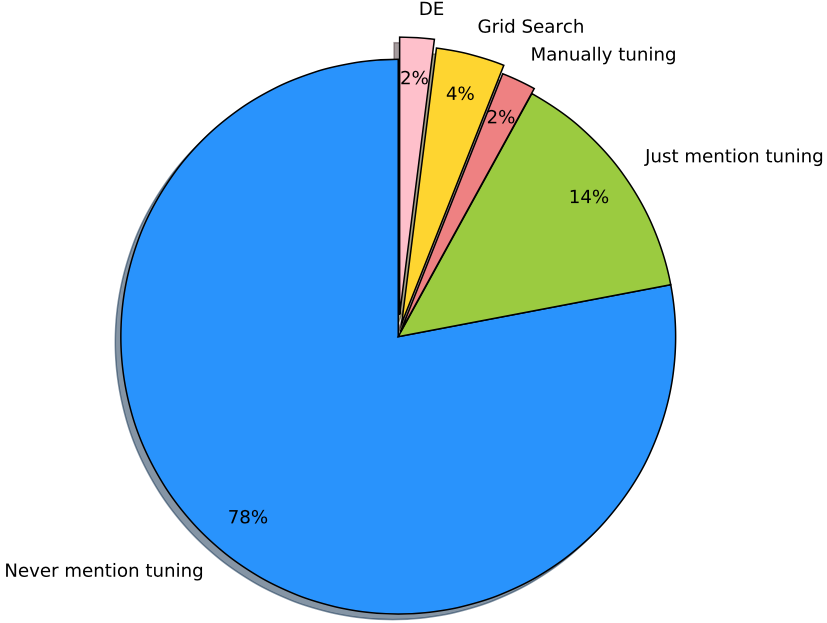
Grid search has been widely used as a parameter tuning method in software engineering community. However, by taking defect prediction task as a case study, we find that differential evolution as a parameter tuner performs if not better, at least as good as grid search but it runs 210X faster.
Tianpei Xia, Wei Fu, Rui Shu, Tim Menzies
arXiv Preprint, 2020
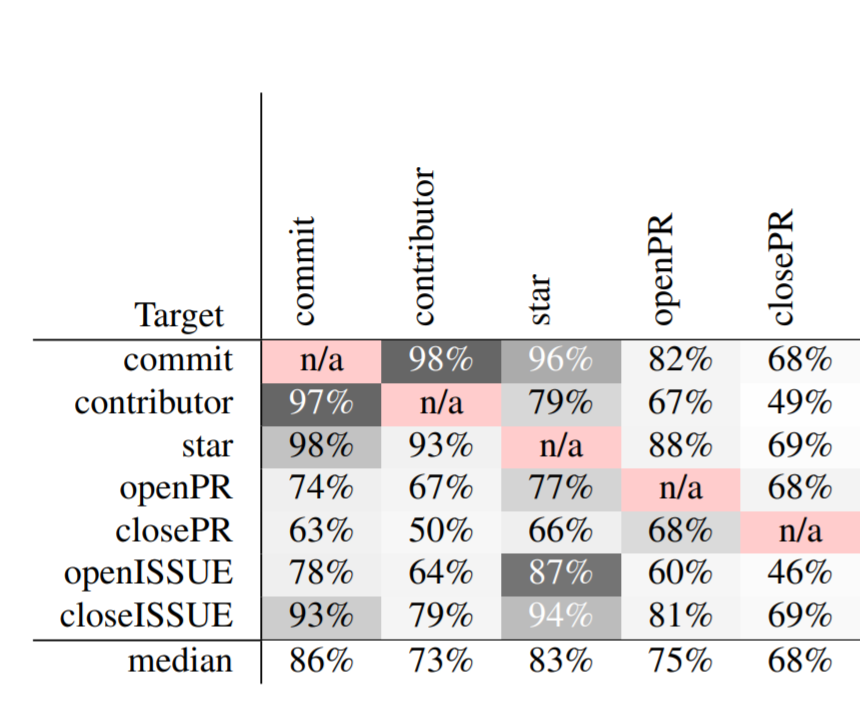
Software developed on public platforms are a source of data that can be used to make predictions about those projects. While the activity of a single developer may be random and hard to predict, when large groups of developers work together on software projects, the resulting behavior can be predicted with good accuracy. In this study, we use 78,455 months of data from 1,628 GitHub projects to make various predictions about the current status of those projects. The predicting error rate can be greatly reduced using DECART hyperparameter optimization.
Amritanshu Agrawal, Wei Fu, Di Chen, Xipeng Shen, Tim Menzies
Transactions on Software Engineering(TSE), IEEE, 2019 (accepted).
Hyperparameter optimization is unnecessarily slow when optimizers waste time exploring redundant options. By ignoring redundant tunings, the DODGE hyperparameter optimization tool can run orders of magnitude faster, yet still find better tunings than prior state-of-the-art algorithms (for software defect prediction and software text mining)
Amritanshu Agrawal, Wei Fu, Tim Menzies
Information and Software Technology (IST), 2018
LDA suffers from “order effects”. Applying differential evolution algorithm to tune LDA parameters will dramatically reduce clustering instability and it also leads to improved performances for supervised as well as unsupervised learning.
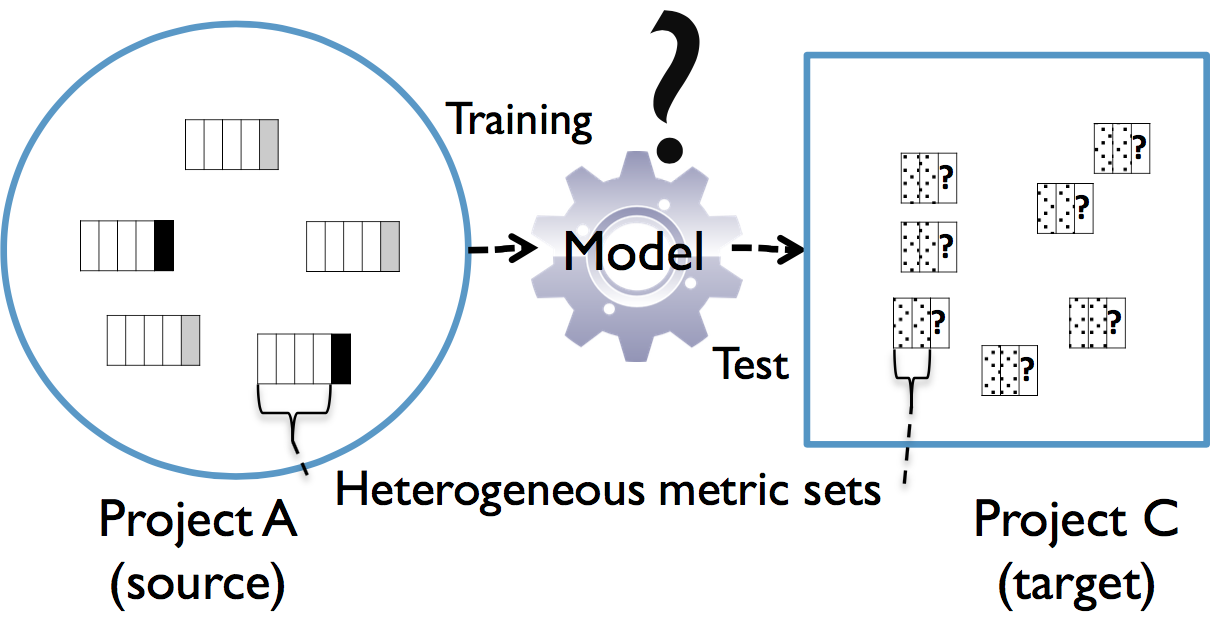
Jaechang Nam, Wei Fu, Sung Kim, Tim Menzies, Lin Tan
Transactions on Software Engineering(TSE), IEEE, 2017.
Our HDP approach conducts metric selection and metric matching to build a prediction model between projects with heterogeneous metric sets. Our empirical study on 28 subjects shows that about 68% of predictions using our approach outperform or are comparable to WPDP with statistical significance.
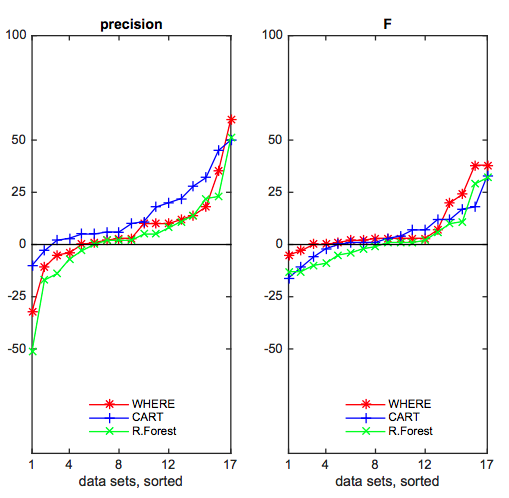
Wei Fu, Tim Menzies, Xipeng Shen
Information and Software Technology (IST) 76 (2016): 135-146.
We applied differential evolution algorithm to explore the hyper-parameter space to learn the best optimal parameters for defect prediction, which improves learners' performance in most cases and terminates quickly.
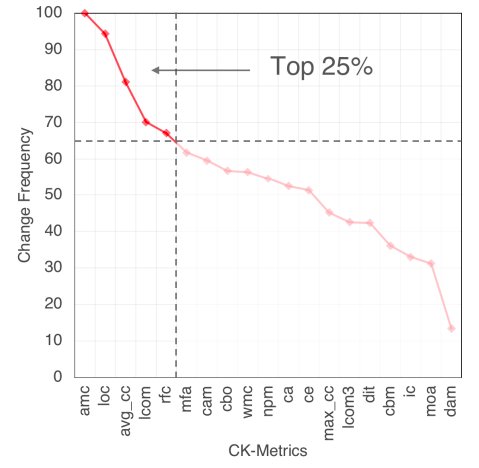
Di Chen, Wei Fu, Rahul Krishna, Tim Menzies
FSE'18
Actionable analytics are those that humans can understand, and operationalize. What kind of data mining models generate such actionable analytics? According to psychological scientists, humans understand models that most match their own internal models, which they characterize as lists of “heuristic” (i.e., lists of very succinct rules). This paper assessed Fast-and-Frugal Tree for software analytics.
Suvodeep Majumder, Nikhila Balaji, Katie Brey, Wei Fu, Tim Menzies
MSR'18
Deep learning methods are useful for high-dimensional data and are becoming widely used in many areas of so ware engineering. Deep learners utilizes extensive computational power and can take a long time to train– making it di cult to widely validate and repeat and improve their results. In this study, we apply local learning on the data sets. Such method is over 500 times faster than deep learning but has similar or better results.
Vivek Nair, Amritanshu Agrawal, Jianfeng Chen, Wei Fu, George Mathew,Tim Menzies, Leandro Minku, Markus Wagner, Zhe Yu
MSR'18
This paper introduces Data-Driven Search-based Software Engineering (DSE), which combines insights from Mining Software Repositories (MSR) and Search-based Software Engineering (SBSE). This paper aims to answer the following three questions: (1) What are the various topics addressed by DSE? (2) What types of data are used by the researchers in this area? (3) What research approaches do researchers use? The paper brie y sets out to act as a practical guide to develop new DSE techniques and also to serve as a teaching resource.
Wei Fu, Tim Menzies
FSE'17 Slides
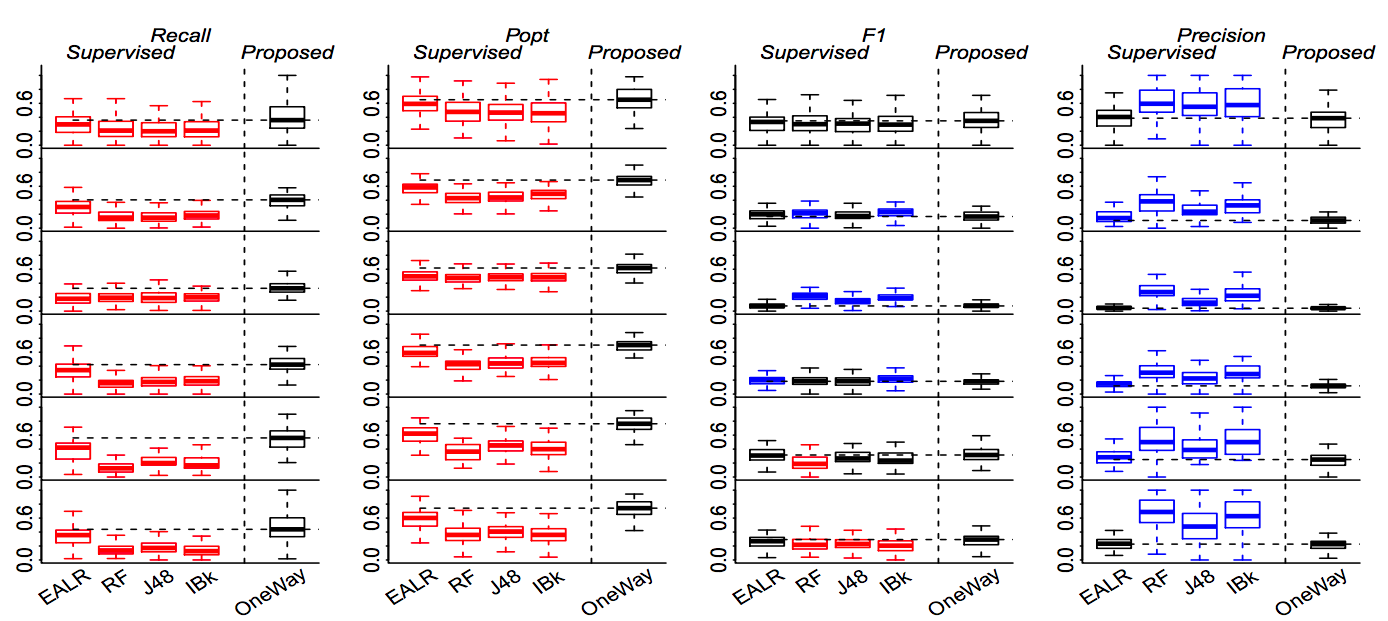
This paper repeats and refutes Yang et al's FSE'16 paper (1) There is much variability in the efficacy of the Yang et al. models, some supervised data is required to prune weaker models. (2) When we repeat their analysis on a project-by-project basis, supervised methods are seen to work better.
Wei Fu, Tim Menzies
FSE'17 Slides
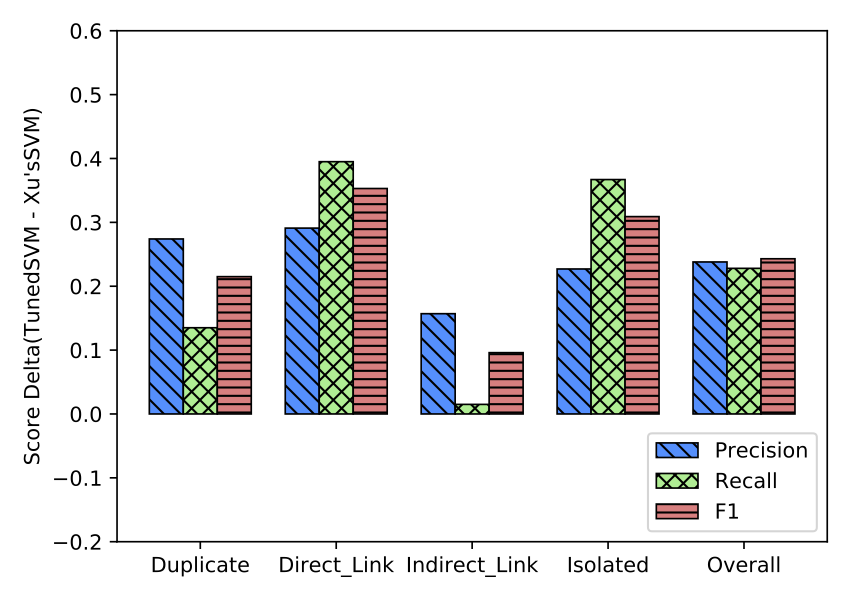
SVM with a simple differential evolution-based parameter tuning can get better performance than deep learning(CNN) method for knowledge units relateness classification task on Stack Overflow. At the same, it is 84X faster than the deep learning method.

Rahul Krishna, Tim Menzies, Wei Fu
ASE'16
We find a "bellwether" effect in software analytics. Given N data sets, we find which one produces the best predictions on all the others. This "bellwether" data set is then used for all subsequent predictions.
